Tutorial 0: Overview of MMFewShot Detection¶
The main difference between general classification task and few shot classification task is the data usage. Therefore, the design of MMFewShot targets at data flows for few shot setting based on mmdet. Additionally, the modules in mmdet can be imported and reused in the code or config.
Design of data flow¶
Since MMFewShot is built upon the mmdet, all the datasets in mmdet can be configured in the config file. If user want to use the dataset from mmdet, please refer to mmdet for more details.
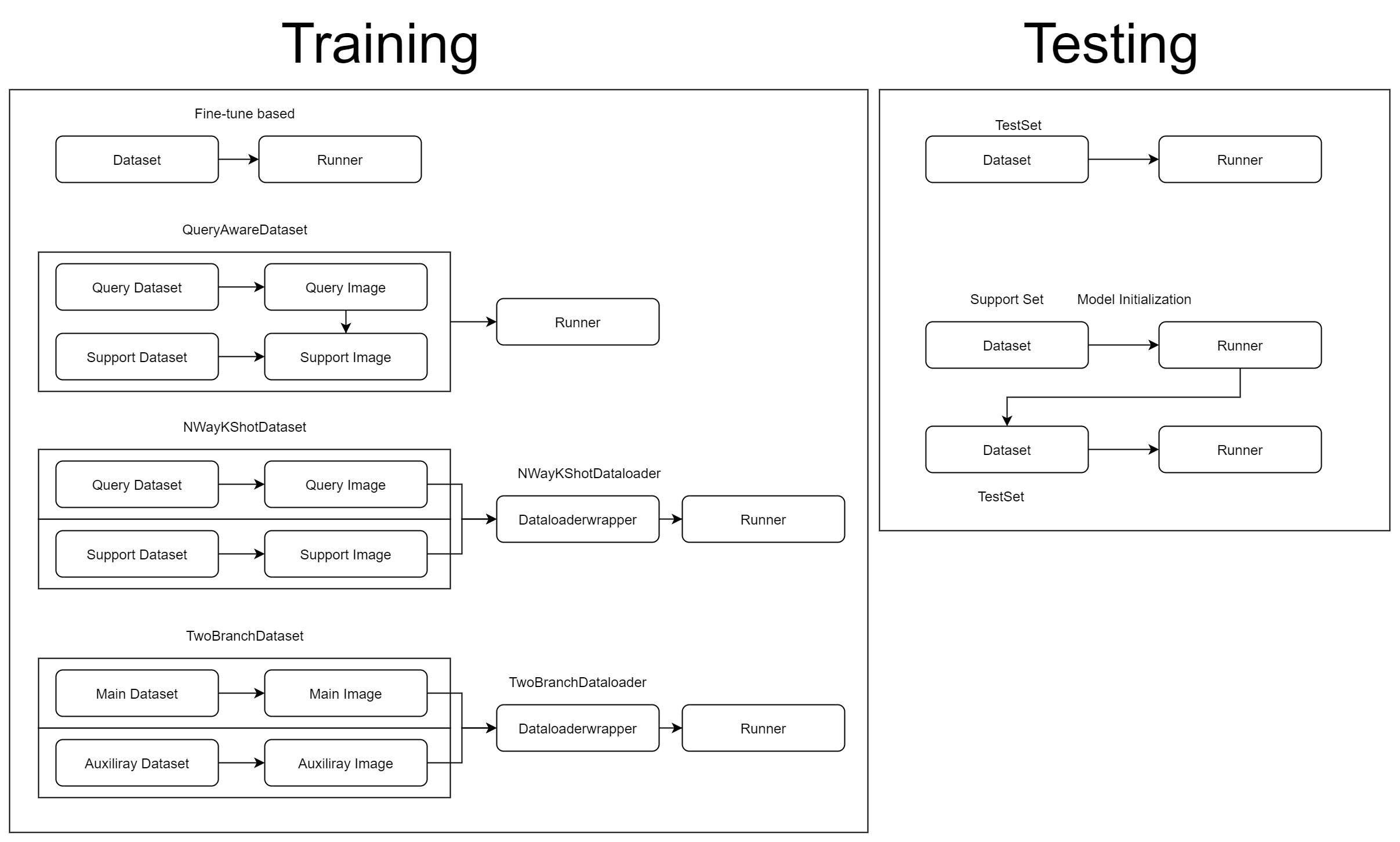
In MMFewShot, there are three important components for fetching data:
Datasets: loading annotations from
ann_cfgand filtering images and annotations for few shot setting.Dataset Wrappers: determining the sampling logic, such as sampling support images according to query image.
Dataloader Wrappers: encapsulate the data from multiple datasets.
In summary, we currently support 4 different data flow for training:
fine-tune based: it is the same as regular detection.
query aware: it will return query data and support data from same dataset.
n way k shot: it will first sample query data (regular) and support data (N way k shot) from separate datasets and then encapsulate them by dataloader wrapper.
two branch: it will first sample main data (regular) and auxiliary data (regular) from separate datasets and then encapsulate them by dataloader wrapper.
For testing:
regular testing: it is the same as regular detection.
testing for query-support based detector: there will be a model initialization step before testing, it is implemented by
QuerySupportEvalHook. More implementation details can refer tommfewshot.detection.core.evaluation.eval_hooks
More usage details and customization can refer to Tutorial 2: Adding New Dataset